
Why legacy and SaaS data modeling architectures fall short...
... and how Hackolade Studio gets it right
Legacy client-server modeling tools are costly, rigid, and poorly aligned with modern DevOps workflows. SaaS-only alternatives may appear more convenient, but they come with significant trade-offs: vendor lock-in, loss of control over sensitive metadata, and limited flexibility.
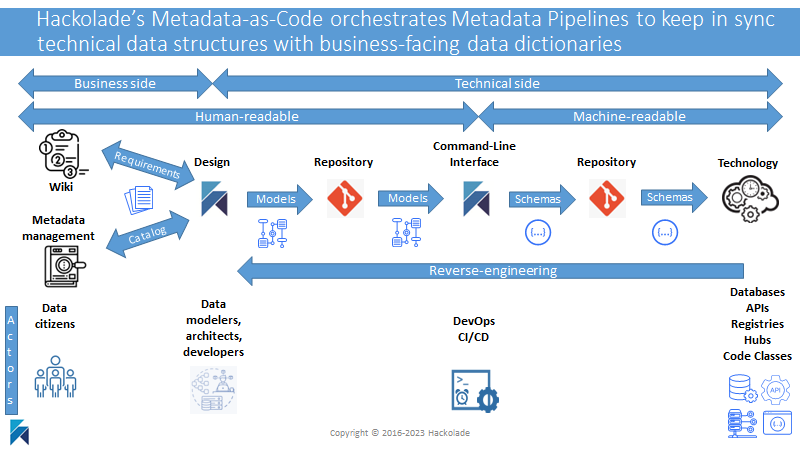
Hackolade Studio offers a smarter path forward with a serverless, open, Git-native architecture. Models are stored in human-readable JSON under the customer’s full control, directly in the organization’s existing Git repositories (GitHub, GitLab, Bitbucket, or Azure DevOps Repos.) This design eliminates the need for proprietary infrastructure, reduces complexity and cost, and ensures that organizations maintain ownership of their intellectual property. By leveraging Git, Hackolade enables full collaboration with versioning, branching, merging, peer review workflows, and all the benefits of distributed source control, allowing teams to work in parallel with confidence. Seamless integration into CI/CD pipelines further strengthens security, compliance, and long-term adaptability, providing a future-proof foundation for enterprise-scale data modeling.
Collaboration is friction-less. Through its browser-based deployment, Hackolade Studio makes it exceptionally easy to socialize and share data models across teams and stakeholders, giving both business and technical users direct access to models without local installation or file management.
Finally, Hackolade Studio extends its value with automated workflows. Its Command-Line Interface, optionally containerized in Docker, enables automated validation, generation, and deployment of models within CI/CD pipelines. Data models are treated as version-controlled, first-class artifacts, reducing manual effort, improving consistency, and accelerating time-to-value.
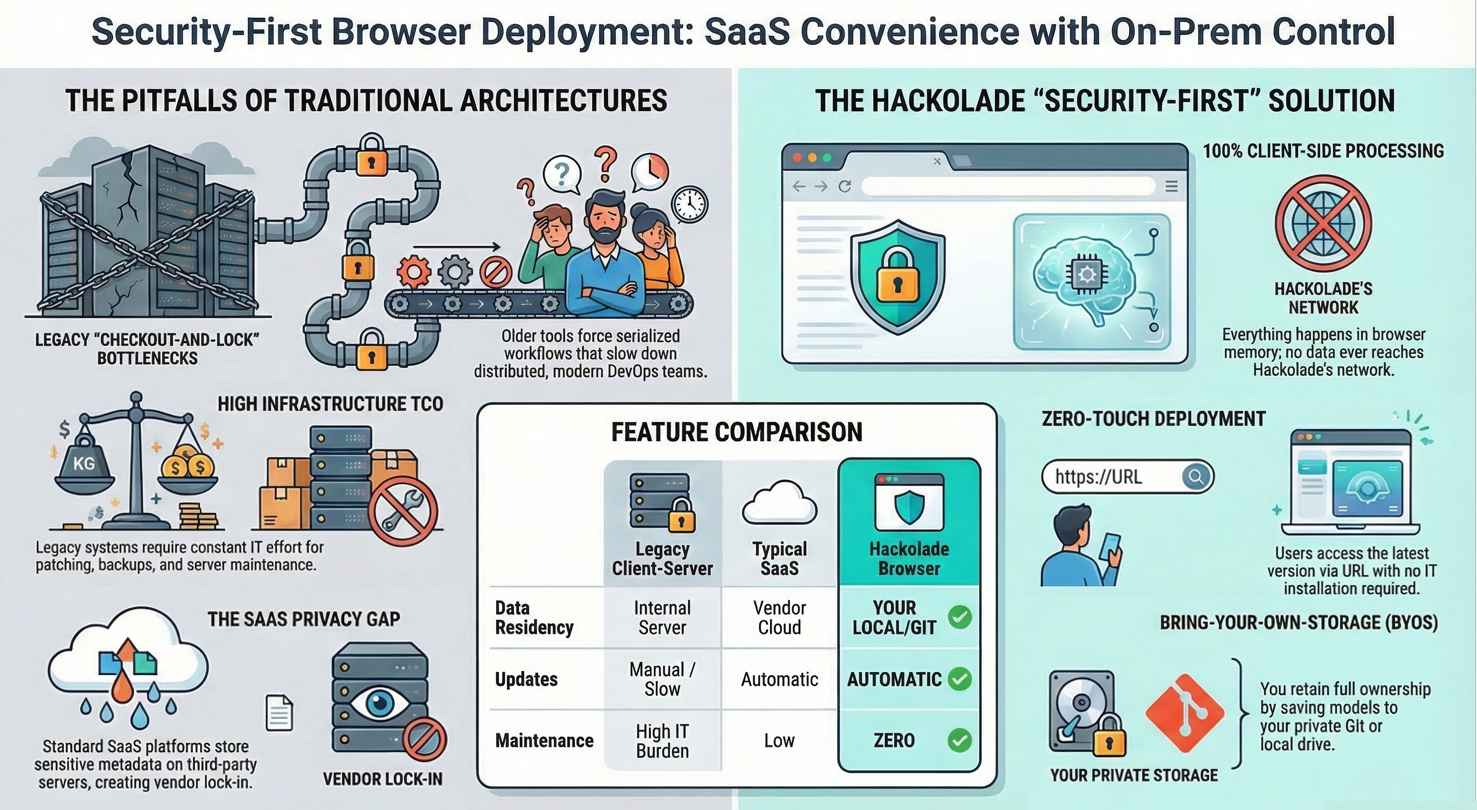
The problem with legacy client-server architectures
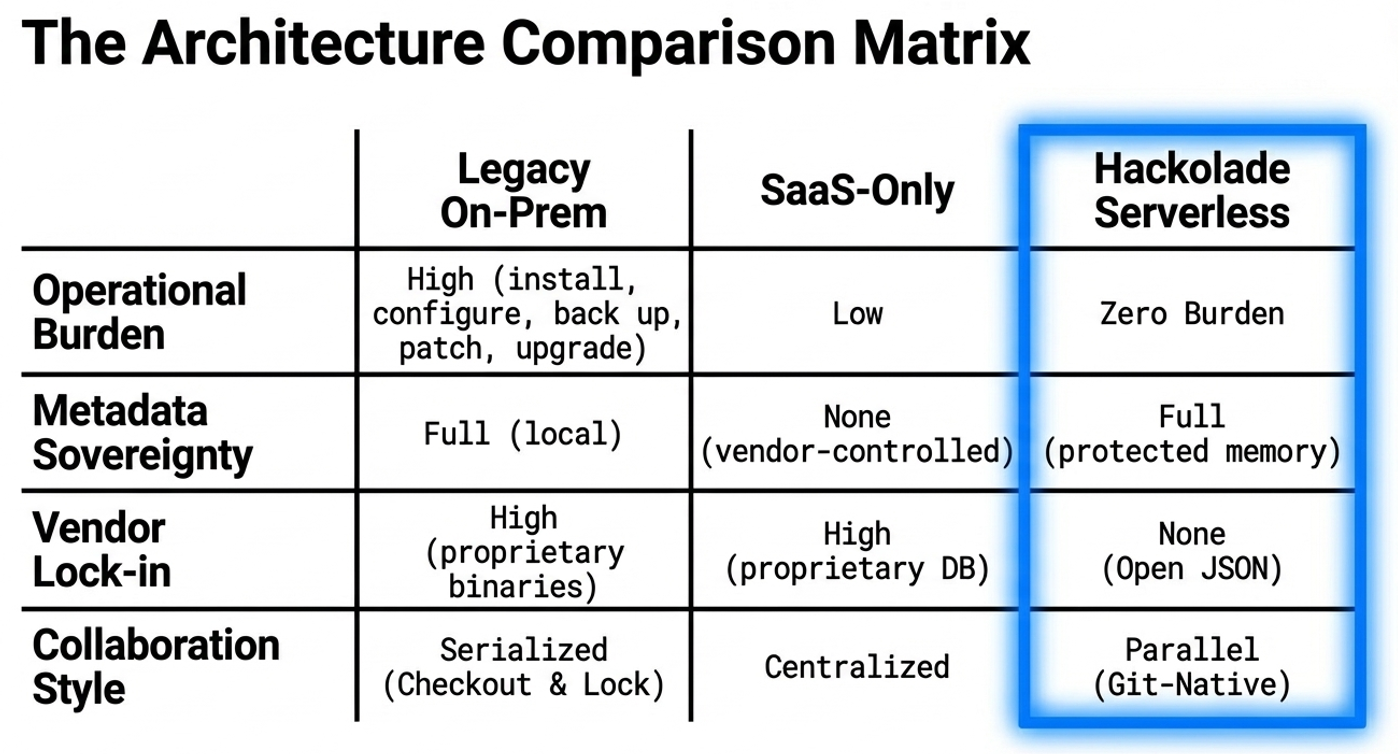
Most legacy data modeling tools were designed in a different era, when client-server architectures dominated. They call their solutions "model mart" or "team server". Their reliance on proprietary binary file formats stored in centralized, on-premises repositories may have been adequate decades ago, but in today’s distributed, cloud-driven environments it has become a liability. These repositories are inflexible, since their proprietary formats lock organizations into vendor ecosystems and make it difficult to integrate with other tools. They also tend to become performance bottlenecks, creating single points of failure and slowing down access for geographically distributed teams. On top of this, maintaining the infrastructure is costly. IT teams must devote time and resources to installing, configuring, backing up, patching, and upgrading systems that add operational overhead without creating strategic value. Perhaps most importantly, these architectures struggle to align with modern DevOps practices. Because they are not designed for continuous integration and deployment pipelines, it becomes cumbersome to manage data models "as code", leaving organizations with brittle workflows and increasing their technical debt.
For collaboration, legacy data modeling tools still rely on a checkout-and-lock paradigm, where a model must be locked by one user before changes can be made and then checked back in. This serialized workflow not only creates bottlenecks but it does not scale well, and it discourages parallel work, since teams must wait their turn to contribute. It mirrors the limitations of older application code version control systems like SVN, where collaboration was rigid and linear, often leading to inefficiency, conflicts, and frustration.
Limitations include:
- Lack of flexibility: proprietary file formats lock users into a vendor-specific ecosystem, making it difficult to integrate with other tools or adapt to evolving technology stacks
- Performance bottlenecks: centralized repositories often become single points of failure or slow access for distributed teams, hampering collaboration
- High Total Cost of Ownership (TCO): organizations must install, configure, back up, patch, and upgrade these servers regularly, an overhead that consumes IT resources without delivering strategic value
- Barriers to DevOps integration: proprietary repositories are poorly suited to CI/CD workflows, making it cumbersome or impossible to treat data models "as code" alongside application development
- Operational fragility: dependencies on legacy infrastructure increase technical debt and create risks when vendors discontinue support or force costly upgrades
- Serialized collaboration: relying on a checkout-and-lock workflow forces teams to work sequentially and wait for others to check in changes, which limits parallel work, slows iteration, and increases the risk of conflicts and inefficiency
In short, this 20th-century architecture cannot keep up with the distributed, API-driven, and DevOps-enabled data environments of today.
The Hidden Pitfalls of SaaS-Only Solutions
In contrast, SaaS-based data modeling platforms emerged with the promise of eliminating infrastructure headaches. However, they introduce a different set of challenges. Typically, SaaS vendors store customer models inside their own proprietary databases. This arrangement creates dependency on the provider’s platform and makes it difficult, if not impossible, to export models into open, reusable formats. As a result, integration with enterprise DevOps pipelines or metadata ecosystems is limited, and organizations often find themselves locked into a single vendor. Accessing or retrieving models outside of the provider’s portal can also be constrained, and for many enterprises, the fact that sensitive metadata resides on third-party infrastructure raises legitimate concerns about confidentiality, compliance, and data sovereignty. What SaaS gains in convenience, it often loses in control and long-term flexibility.
The issues are summarized here:
- Vendor lock-in: customers are dependent on the SaaS provider’s platform for as long as they use the tool, with no straightforward way to export models into open formats
- Limited integration: with models trapped in the provider’s environment, it becomes difficult to integrate seamlessly into enterprise DevOps pipelines or metadata ecosystems
- Restricted access: even retrieving models outside of the provider’s portal can be cumbersome or, in some cases, impossible
- Data confidentiality concerns: sensitive metadata and data definitions may reside outside the organization’s control, creating compliance or regulatory risks
While SaaS removes the infrastructure burden of on-prem repositories, it does so at the expense of control, portability, and integration flexibility.
Hackolade Studio: a modern, serverless, Git-native architecture
Hackolade Studio takes a very different path, one that combines the usability and collaboration benefits of modern platforms with the openness and control that enterprises require. Instead of relying on proprietary repositories or vendor-controlled databases, the architecture of Hackolade Studio is serverless, and models are stored in human-readable JSON format, managed directly in the organization’s own Git repositories. This design eliminates the need for complex, dedicated infrastructure, reduces operational burden, and ensures that models are always portable and under the customer’s control. Because metadata is treated "as code", Hackolade Studio integrates seamlessly into CI/CD pipelines, allowing data models to evolve at the same pace as application development and deployment. This approach also aligns naturally with the workflows of modern data engineering teams, who are already accustomed to Git-based collaboration.
For collaboration, Hackolade Studio replaces the outdated checkout-and-lock paradigm paradigm of legacy tools with a Git-native approach that enables distributed, parallel collaboration. Multiple team members can work on different parts of a model simultaneously, merging changes as needed with the same flexibility developers enjoy in modern software engineering. This approach removes bottlenecks, accelerates iteration, and fosters true teamwork, delivering for data modeling the same kind of revolution Git brought to code development.
Hackolade Studio makes it exceptionally easy to socialize and share data models across teams and stakeholders through its browser-based deployment option. This approach enables users to access the full modeling environment directly from a web browser, with no local installation required and no dependency on locally stored model files. Stakeholders across business and technical teams can participate in data modeling activities with minimal friction, accelerating alignment and decision-making.
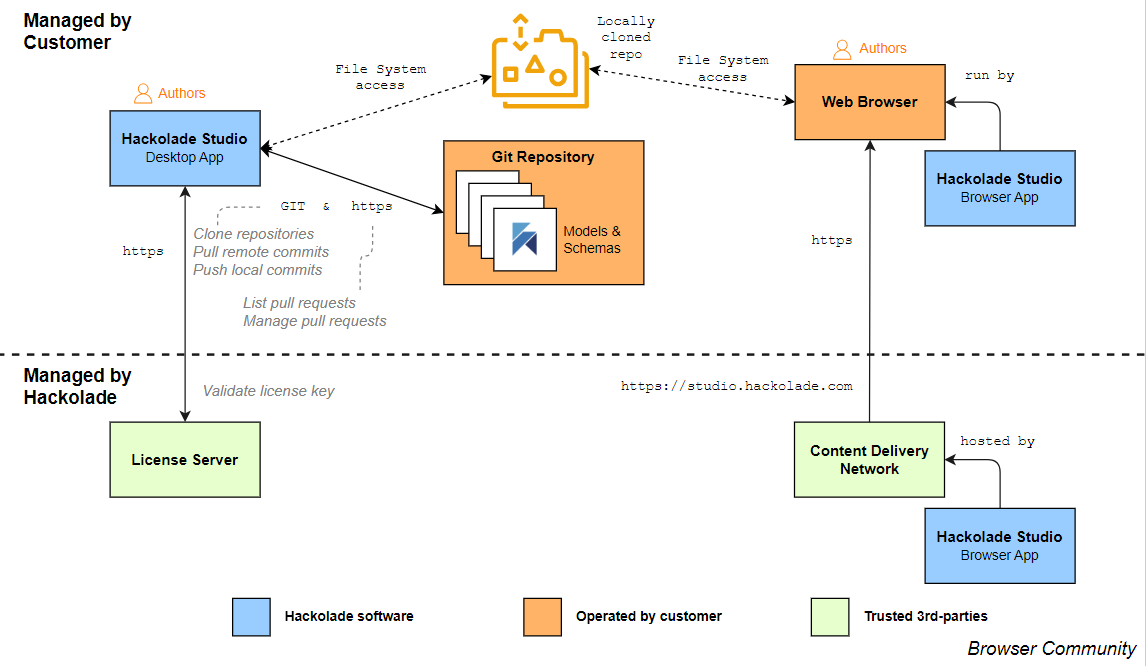
The result is an architecture that is not only lighter and more secure, but also inherently future-proof. Organizations can socialize and govern their models across teams without bottlenecks, maintain full ownership of their intellectual property, and ensure compliance with data residency requirements. By leveraging the ubiquity of Git and the transparency of JSON, Hackolade Studio delivers what neither legacy client-server systems nor SaaS-only solutions can: a flexible, scalable, and governance-friendly foundation for enterprise data modeling in the 21st century.
Hackolade Studio not only offers a lightweight, easy-to-activate architecture with lower total cost of ownership and more fluid collaboration, but it also provides a Command-Line Interface, optionally containerized in Docker, enabling organizations to orchestrate automated workflows in their CI/CD pipelines. By integrating the CLI with scheduling or event-driven triggers, teams can automatically validate, generate, and deploy models as part of their standard DevOps processes, ensuring consistency and quality across the data lifecycle. This approach bridges the gap between modeling and engineering practices, allowing enterprises to treat data models as first-class, version-controlled artifacts, reduce manual effort, and accelerate time-to-value, all while maintaining the security, governance, and flexibility that modern organizations demand.
This architecture offers decisive advantages:
- Openness and portability: JSON-based models are fully transparent and easily integrated into other tools and workflows
- Native DevOps alignment: by treating metadata "as code" in Git, Hackolade Studio integrates seamlessly into CI/CD pipelines, enabling automated validation, governance, and deployment
- No vendor lock-in: customers own their models outright and are free to move them between tools, teams, or environments as they wish
- Low operational burden: there is no proprietary repository server to install, maintain, back up, or upgrade, thereby dramatically reducing cost and complexity
- Security and sovereignty: models stay entirely within the customer’s infrastructure (on-premises or cloud), ensuring compliance with data residency and governance requirements
- Parallel, distributed collaboration: leverages Git to allow multiple users to work on models simultaneously. This enables true parallel development, faster iteration, and collaborative workflows
- Browser-based collaboration: teams and stakeholders can easily access the full modeling environment directly from a web browser, with no local installation or local model files required, enabling seamless participation across business and technical roles and accelerating alignment and decision-making.
By leveraging the ubiquity of Git and the simplicity of JSON, Hackolade Studio achieves what neither legacy nor SaaS solutions can: a flexible, future-proof, and governance-friendly platform for data modeling in the modern enterprise, where data models can be easily shared across the organization.
Model Hub: Serverless by Design, with Complete Customer Control
With the introduction of the Model Hub and its database component, how does Hackolade reconcile this with its stated serverless architecture principles?
The Hackolade Model Hub introduces a modern, lightweight approach to model-driven metadata management. Although it leverages a database, this architecture remains fundamentally serverless, and critically, under the full control of the customer.
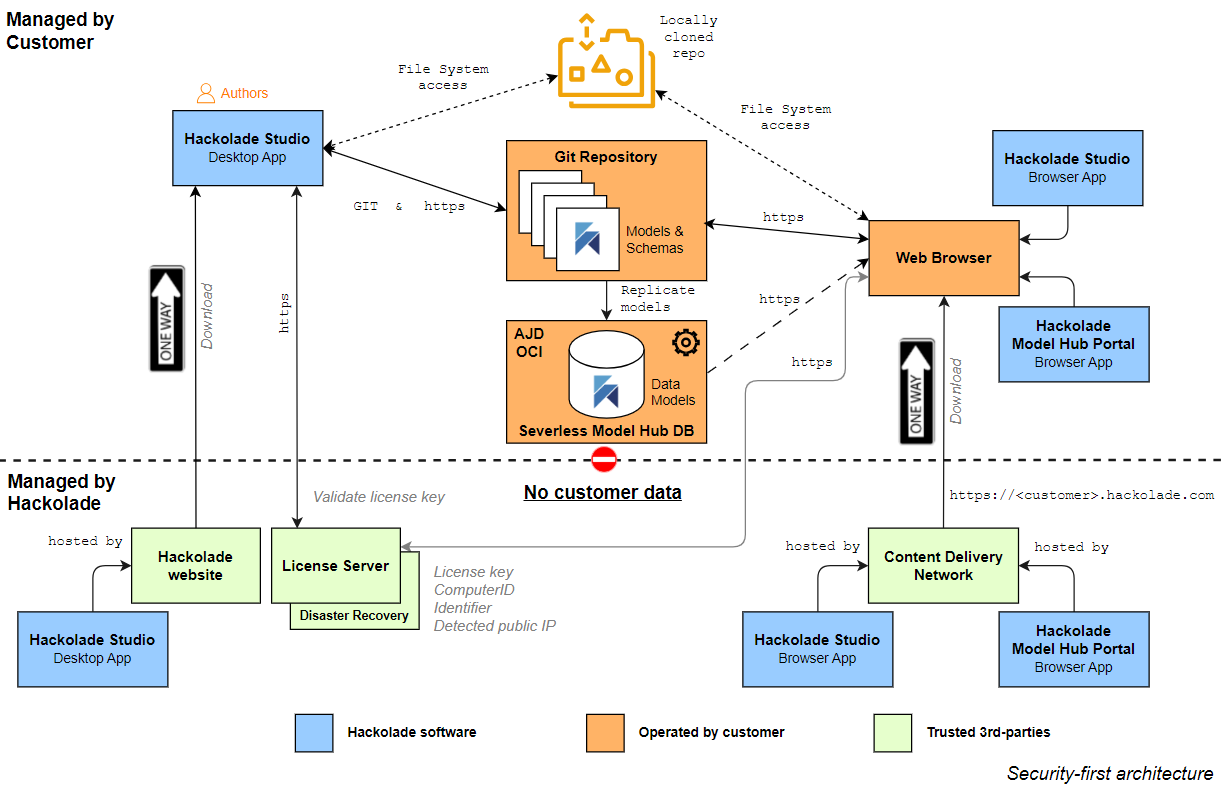
Here's how it works:
- Customer-hosted infrastructure on preferred cloud provider: unlike traditional SaaS platforms where your models are stored in vendor-controlled systems, the Model Hub’s database is deployed entirely within the customer’s cloud infrastructure account. You start the database, using a script provided by Hackolade, ensuring that no one outside your organization, including Hackolade, can access your models.
- Local residency, external app delivery: while your data stays securely in your cloud account, the Model Hub’s user interface runs as a static application delivered via a content delivery network such as Azure Front Door or AWS CloudFront to your browser where it runs locally. This setup guarantees you always access the latest application version, without installing or managing enterprise applications.
- Database acts as coordination, not a silo: the database stores your data models, created and maintained in Hackolade Studio, in their open JSON format, preserving transparency and alignment with Metadata-as-Code principles. However, the Hub’s database serves strictly as a lightweight coordination layer, enabling features like search, lineage, and discovery, not as a centralized repository removed from your control.
- Zero data ex-filtration, maximum compliance: the design ensures that none of your sensitive data ever leaves your infrastructure. Hackolade collects no telemetry, uses no cookies, and includes no tracking capabilities. This architecture is purpose-built to satisfy stringent data protection standards.
Why this architecture matters
- You retain full sovereignty over your model files and intellectual property, with no risk of vendor lock-in.
- The Model Hub requires no proprietary repository setup, minimizing deployments, upgrades, backups, or maintenance efforts.
- You get the benefits of a collaborative, model-driven metadata platform with search, lineage, governance, and without ceding control or introducing risk.
- Combining serverless convenience with customer-controlled deployment offers the best of both worlds: agility and security.