
How to organize models
Now that you have a good technical understanding of the modular capabilities of Hackolade Studio, you may ask yourself how you should organize your models: one giant monolithic model vs a handful of models vs many small models? And if small, how should they be organized: by type of modeling (conceptual, logical, physical), by domain, by line of business, by persona? In one mono-repository or multiple repositories? And what folder structure to use in the repositories?
There is no good nor bad response to these questions. You must experiment some to understand the various options, and how they play out with Hackolade Studio. But mostly, you must ensure that the granularity and structure of your storage matches the needs and constraints of your organization. You may also start with one approach, to later evolve towards another one.
How to Avoid Misusing Containers in Hackolade Studio
When first starting to work with a Polyglot data model in Hackolade, a new user might be tempted to use "containers", for example one container per domain. After all, it is a rectangle with a name and a color, and it seems to be useful to group entities.
But it is important to define containers in Polyglot models with a physical alignment in mind. Each polyglot container, when derived into a physical model will map to the equivalent object in the target technology of that model:
- RDBMS: (user) schema
- Avro/JSON: namespace
- Cassandra/ScyllaDB: keyspace
- CosmosDB: container
- Couchbase (up to 6.5): bucket
- Couchbase (7 and up): scope
- Elasticsearch: index
- MongoDB/Neo4j: database
- Parquet/Protobuf: file
etc.
This container object appears in DDL and schema artifacts.
As a result, in a Polyglot model, you should not use containers to organize your model visually and logically, if they will be deployed physically in a different manner. While your polyglot model is, in theory, technology-independent, it is wise to define it with awareness of the physical consequences.
But it does make sense to want to group entities together and make large models easier to understand and navigate. Several alternatives are possible.
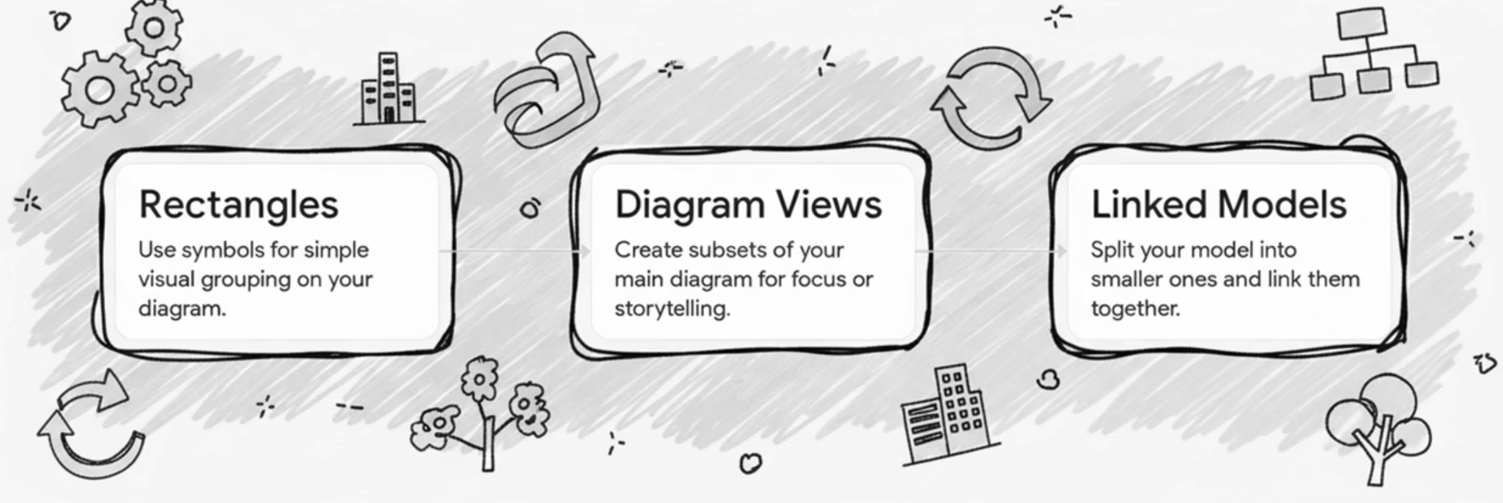
- Rectangles: you may want a way to visually group entities that should be logically associated to each other, by creating one or more rectangle symbols in your diagram.
- Diagram Views: you may want to create a subset of the main ER diagram, and be able to use different display options than the main ER Diagram, for example for data model story telling.
- split your model into smaller individual models, then link them up:
- either via references to external definitions (at the entity level or attribute level),
- or a reference to one or more polyglot models.
Some organizations might tempted to split models so that multiple users can make changes to different parts of models without stepping on each other's toes. This argument should not be the driving factor. Because, with Hackolade Studio data models having their lifecycle entirely managed in Git repository providers, this argument should never be a reason for concern. We're no longer in a collaboration constrained, like with legacy tools, by the Checkout plus Lock then Checkin paradigm. With Git, we've got a distributed collaboration that allows many users to collaborate in parallel on the same model file without any fear of loss of data or conflicts.
A better question to ask yourself is about separation of concerns and user rights to make changes. One large customer of ours has a department responsible for the canonical definitions of corporate-wide objects or dimensions (such as data, time, address, etc.) Each Line of Business might have its own center of excellence for the semantic definition and ontology of their LOB. And a modeler might be responsible for the assembly of all the entities and attributes of a Data Product, based on existing objects from the corporate level as well as multiple LOBs.
The operational context of your organization as well as its rules and constraints should be driving whether you have one or more repositories, plus who has access to them. Then how the folder structure of each repository should be organized. One possible organization of folder could be by domain of the LOB.
Don't forget that we support an optional fork & pull strategy, plus that our solution allows to reference external definitions or polyglot models across multiple repositories, and even across multiple repo providers.
Remember also that Git automatically versions model changes. Each commit is an immutable version of each model file, allowing for a visible and traceable history of every change.
If you want to manage different environments, each with its own lifecycle (e.g.: dev, test, acceptance, prod...) you should leverage the Git branching capabilities.
You may fear that by having too many small models, you might lose track of how all these models relate to each other, particular if you have multiple hops with transitive references? Do not worry: with our Hackolade Model Hub, you can see the lineage between models as well as a where-used table, proving an impact analysis capability.
Tips to organize data models for teams: containers, domains, collaboration, and governance
- Domain-driven modeling
- Use domains to define ownership boundaries (People, Product, Finance…).
- Keep shared master data in dedicated domain(s) with clear ownership.
- Container management
- Create containers to structure entities with an eye on physical derivation (schema/keyspace/namespace).
- Avoid using containers solely as a collaboration boundary if that conflicts with physical targets.
- Collaboration with Git
- Use distributed version control for concurrent work without locks.
- Branch by feature/domain, open pull requests, and merge with Model Compare & Merge when needed.
- Access control and authorization
- Enforce permissions on the Git server (branch protection, code owners, reviewer policies).
- Use separate repositories or subfolders with protected branches for sensitive master data.
- Export and sharing
- Export models or slices at container/domain level to share limited sets (desktop license or external consumers).
- Generate JSON Schema, Avro, relational DDL, etc., from selected scope.
Setup example
1) Structure the repository
- Root repo (e.g., data-models)
- polyglot/ (main polyglot model and domain folders)
- domains/
- people/
- product/
- finance/
- shared-corporate/
- physical/
- rdbms/
- document/
- graph/
- streaming/
Tip: For highly sensitive master data, keep shared-corporate in a separate repo with stricter permissions, and include it as a Git subtree in the main repo.
2) Define containers with physical alignment in mind
- For each model, create containers that will map to the physical target:
- RDBMS: map container to schema (e.g., product_core, finance_ref).
- Cassandra: keyspace.
- Avro/JSON: namespace.
- Keep the container count purposeful; avoid using containers only to limit editing if that breaks physical mapping.
3) Set up Git collaboration
- Initialize a Git repo (or use existing). Connect Hackolade Studio to the remote.
- Branching model:
- main: protected; production-ready models.
- domain/*: domain teams’ integration branches (e.g., domain/product).
- feature/*: short-lived branches for specific changes.
- Enable PR checks: schema validation, lints, required reviewers and maintainers
4) Protect master data and critical domains
- Use Git server controls:
- Branch protection on main and shared-corporate branches.
- Maintainers to enforce reviews from owning teams.
- Optional: separate repo for shared-master with stricter access; pull via subtree.
5) Compose data products across domains
- When a product needs entities from multiple domains, reference the shared entities for maintainability and consistency, rather than duplicating or importing.
- Use Model Compare & Merge to reconcile branch changes into the parent Polyglot model.
- Maintain clear dependency documentation between product models and shared-corporate.
6) Derive from Polyglot into physical models
- Generate downstream artifacts from the chosen scope:
- JSON Schema for API or event contracts
- Avro schemas for streaming
- Relational DDL for RDBMS
- Store generated artifacts under physical/ subfolders by target technology and environment.
7) Review, validate, and publish
- Validate models in Studio (consistency checks, references, naming rules).
- Create PRs with a change summary. Use the diff in Model Compare & Merge for reviewers.
- On approval, merge to main (and evaluate whether tagging a release makes sense (e.g., vYYYY.MM.DD).) Your documentation portal can point to the latest main or tagged release.
Practical illustration
Example A: People master shared across domains
- Context: People entities (Person, Address, Identity) are shared by HR, CRM, and Finance.
- Setup:
- Domain: Shared Corporate
- Container: people_master (maps to RDBMS schema or namespace)
- Git: separate repo with protected main; included as subtree in data-models
- Workflow:
- HR proposes a change in feature/people-id-verification
- PR requires Shared Corporate owners’ review
- On merge, downstream schemas regenerated (CI) and published for consumers
Example B: Finance reference data with restricted edits
- Context: Currency, TaxRate entities used across domains; only Finance team may change.
- Setup:
- Domain: Finance
- Container: finance_ref (maps to keyspace/schema/namespace)
- Git: single repo; branch protection + required Finance reviewers
- Workflow:
- Product domain needs a new attribute on Currency
- They open an issue + PR; Finance reviewers must approve before merge
Example C: Export a limited model for a vendor
- Context: External vendor needs only Order and Payment entities.
- Steps:
- In Studio, select the OrderMgmt container and Payment subdomain
- Export JSON Schemas and a light documentation bundle
- Share exported artifacts without exposing full enterprise model
Best practices for teams
Modeling and structure
- Design domains around business capabilities. Keep master data centralized and versioned.
- Use containers to mirror physical targets. Avoid container sprawl.
- Standardize naming conventions for domains, containers, entities, and attributes.
Collaboration
- Prefer short-lived feature branches and frequent merges to reduce drift.
- Use Model Compare & Merge to resolve conflicts and keep polyglot + physical views aligned.
- Document change intent in PR descriptions with links to user stories/tickets.
Governance and access control
- Enforce owners/maintainers and branch protection on critical areas.
- For high-sensitivity master data, use a separate repo and subtrees; restrict write access.
- Establish a deprecation policy and versioning strategy for breaking changes.
Release and distribution
- Automate validation and artifact generation in CI (JSON Schema, Avro, DDL) for each PR and on main.
- Tag releases and publish artifacts to an internal registry or documentation site.
- Export model slices for targeted sharing with partners/vendors.
Operational hygiene
- Regularly clean unused branches. Archive deprecated containers/entities with clear annotations.
- Keep references healthy: avoid duplication; prefer shared definitions.
- Periodically review domain boundaries as org structures evolve.
Frequently asked questions
Q: Should we use containers to isolate team work?
A: Prefer Git-based isolation (branches, repos, permissions). Use containers primarily to reflect physical mapping (schema/keyspace/namespace). This avoids mismatch when deriving physical models.
Q: How do we prevent people from “stepping on each other’s toes”?
A: Git enables concurrent (simultaneous) edits; conflicts are resolved on merge. Combine this with owners/maintainers, branch protection, and required reviews.
Q: How do we apply the same authorization in Git to exported schema files?
A: Generate artifacts into protected folders/branches or separate repos with appropriate permissions. Use CI to gate changes and enforce code owner reviews.
Next steps
- Set up domains and containers in your Polyglot model per the guidance above.
- Configure your Git repo with branch protections and maintainers.
- Automate exports in CI for each target platform.
- Socialize the best practices within your teams and iterate.
If you need help tailoring this approach to your environment, contact Hackolade support.